NAND 门:所有数字逻辑的唯一构建块
NAND 门是函数完备的:AND、OR、NOT、XOR 乃至存储单元都可仅由 NAND 构建。CMOS 经济性使其成为标准单元库的主导。

TL;DR: NAND 门只在所有输入同时为 1 时输出 0,否则输出 1 ()。它是函数完备的——任何布尔函数都可仅用 NAND 门实现。在 CMOS 硅工艺中,NAND 比 NOR 用更少的晶体管,且开关更快,这就是它在现代标准单元库中占据主导地位、并使”NAND Flash”得名的原因。
任何电子分销商都能买到的 74HC00 IC,在 14 引脚 DIP 封装里集成了四个 NAND 门,售价仅几美分。然而这颗不起眼的小芯片——以及现代每颗处理器中蚀刻进硅片的数十亿个 NAND 门——代表了工程史上被制造最多的逻辑结构。
本文聚焦 NAND 门作为一种实际、物理元件的方方面面:它在 CMOS 硅工艺中如何被构建、哪些真实的 IC 实现了它、它们的数据手册告诉了我们什么,以及为什么半导体经济学让 NAND 门成为商用数字系统的主导构建块。
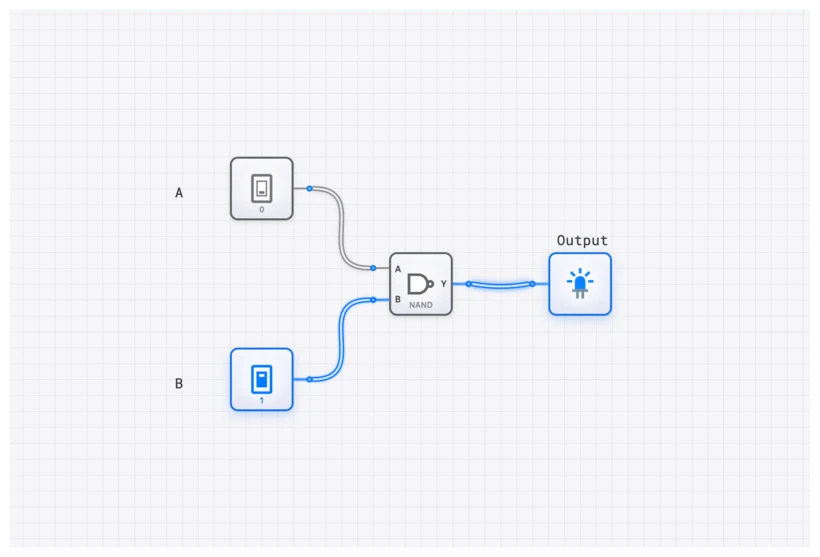
NAND 门:快速回顾
本质上,NAND 门就是一个 AND 门后接一个 NOT 门。它接收两个或更多输入,只要不是所有输入同时为 HIGH,输出就是 HIGH (1);只有当所有输入都为 HIGH 时,输出才为 LOW (0)。
真值表
| 输入 A | 输入 B | 输出 Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
布尔表达式
根据 德摩根定理,它等价于 ,这揭示了 NAND 门的双重身份——它也可以看作输入取反的 OR 门。
CMOS 实现:为什么 NAND 是硅片上的”天然”门
要理解 NAND 为什么在商用 IC 设计中占据主导地位,你得看到晶体管层面。在 CMOS 工艺中,每个逻辑门都由两个互补网络组成:
- 下拉网络 (PDN): 由 NMOS 晶体管把输出连到地 ()。
- 上拉网络 (PUN): 由 PMOS 晶体管把输出连到电源电压 ()。
对一个 2 输入 NAND 门,PDN 中两个 NMOS 晶体管串联,PUN 中两个 PMOS 晶体管并联。这种安排有一个关键优势:NMOS 晶体管(以电子作为载流子)天生比 PMOS 晶体管(以空穴作为载流子)更快。把更快的 NMOS 串联、把更慢的 PMOS 并联,NAND 门就能在最小晶体管尺寸下获得均衡的上升与下降时间。
对比一下 NOR 门——它的 PMOS 晶体管要串联。串联的 PMOS 增加电阻,减慢上拉过程,需要做得更宽(更大)来补偿。这就是为什么在 CMOS 中,一个 2 输入 NAND 门只需要 4 个晶体管,占用的硅片面积也比等价的 NOR 门更小。
相比之下,一个 AND 门需要一个 NAND 加上一个反相器——共 6 个晶体管。这 50% 的晶体管开销正是 ASIC 设计流程中的综合工具尽可能优先 NAND 实现的原因。
真实的 IC:74HC00 与 CD4011
NAND 门作为分立 IC,从 TTL(晶体管—晶体管逻辑)家族最早期就有了。下面两款使用最广泛的 NAND IC 代表了不同的工艺世代:
74HC00:高速 CMOS
74HC00 是 14 引脚 DIP(或 SOIC)封装中的四组 2 输入 NAND 门。它属于 74HC(高速 CMOS)系列,是教学和原型开发场景中最常用的逻辑 IC。
典型数据手册参数( = 5V,25°C):
| 参数 | 符号 | 典型值 |
|---|---|---|
| 电源电压 | 2V 至 6V | |
| 传输延迟(L 至 H) | 9 ns | |
| 传输延迟(H 至 L) | 9 ns | |
| 输出电流(拉电流) | -4 mA | |
| 输出电流(灌电流) | 4 mA | |
| 静态电流 | 1 uA | |
| 扇出(对 74HC 输入) | — | 约 10 |
引脚排列(14 引脚 DIP):
- 引脚 1、2 -> 门 1 输入;引脚 3 -> 门 1 输出
- 引脚 4、5 -> 门 2 输入;引脚 6 -> 门 2 输出
- 引脚 9、10 -> 门 3 输入;引脚 8 -> 门 3 输出
- 引脚 12、13 -> 门 4 输入;引脚 11 -> 门 4 输出
- 引脚 7 -> GND;引脚 14 ->
CD4011:经典 CMOS
CD4011 是 4000 系列家族中的 CMOS 对应款。它的电源电压范围更宽(3V 至 18V),但传输延迟更慢(5V 时通常为 50–125 ns)。它的优势在于极低的功耗和宽电源电压容差,因此在电池供电和工业应用中很受欢迎。
该选哪个:
- 74HC00 适用于面包板项目,以及任何需要 1 MHz 以上时钟同步的应用。
- CD4011 适用于低功耗、宽电压范围、对速度要求不高的应用。
时序规格:读懂数据手册
任何严肃的设计工作,数据手册上的传输延迟数字都是你的硬约束。我们看看这些数字在实际中意味着什么。
74HC00 门的典型 是 9 ns。如果你串联三个 NAND 门(例如用纯 NAND 构造一个 OR 门),关键路径的总延迟约为 ns(信号经过输入反相器和最终的 NAND,而非每个输入都串行经过全部三个门)。
在 50 MHz(20 ns 时钟周期)下,这只剩 2 ns 的时序余量。在 100 MHz 下,延迟已经超过了整个时钟周期。这就是为什么高速设计会用标准单元库里的专用 OR 单元,而不是用分立 NAND 门来组装。
常见陷阱:传输延迟堆叠
当所有逻辑都用 NAND 搭建时,每一级的延迟都会累加。基于 NAND 的 OR 门的关键路径延迟约为 。基于 NAND 的 XOR 门关键路径约为 (三级门)。在复杂电路里,这些堆叠的延迟会限制最高时钟频率,并引入时序冒险——也就是不同路径上的信号到达时间不同所产生的瞬时错误输出,称为毛刺(glitch)。
用示波器进行验证
要在 digisim.io 中观察传输延迟堆叠现象,可以并排搭一个基于 NAND 的 OR 门(三个 NAND)和一个原生 OR 门。给两个电路输入相同的 CLOCK 信号。连接三个示波器通道:一个连 CLOCK 输入、一个连原生 OR 输出、一个连 NAND 版 OR 输出。
你会看到两个输出都跟随时钟,但 NAND 版本相对于原生版本明显向右偏移。那段额外的水平偏移,就是采用纯 NAND 实现所要付出的”延迟税”。
制造优势:NAND 是如何赢得硅片之战的
NAND 门在 IC 制造中的主导地位绝非偶然。它源自三方面相互关联的优势:
1. 晶体管数量
一个 2 输入 NAND 门用 4 个晶体管。AND 门需要 6 个(NAND + 反相器)。OR 门需要 6 个(两个反相器 + NAND)。当你要把 100 亿个晶体管塞进一颗芯片时,门级晶体管数量减少 33% 直接意味着更小的芯片面积、更高的良率、更低的单位成本。
2. 速度
由于 NAND 的 NMOS 下拉网络(对 NAND 来说是速度关键路径)是中等电阻的串联结构,而 PMOS 上拉网络是低电阻的并联结构,因此 NAND 门比同等的 NOR 门切换更快。在先进工艺节点(7 nm、5 nm、3 nm)上,这种速度优势会在数十亿门上累计放大。
3. 标准单元库
现代芯片设计依赖标准单元库——由代工厂提供的预特征化门级布局。这些库高度偏向 NAND。一个典型的库会提供 NAND2、NAND3、NAND4,甚至 NAND2X2(双驱动强度 NAND)等单元,每种都为面积、速度和功耗做过优化。EDA 综合工具会把你的 RTL(寄存器传输级)设计映射到这些单元上,优化器自然倾向于以 NAND 为主的实现,因为它们提供最佳的”面积—延迟—功耗”三者乘积。
真实世界的应用
NAND 闪存
最有名的应用名字本身就用了它:NAND 闪存(NAND Flash)。在 NAND 闪存中,浮栅晶体管串联在一起——拓扑与 NAND 门中 NMOS 下拉网络一致。这种串联让 NAND 闪存比 NOR 闪存(晶体管并联)密度更高,从而支撑现代 SSD、U 盘和智能手机的海量存储容量。
ASIC 地址译码器
在处理器内部,地址译码器决定要访问哪个存储单元或外设。多输入 NAND 门天然实现”匹配此精确比特图样”的功能。对于 4 位地址 1101,译码器把第三位(那个 0)取反,然后把全部四条线接到一个 4 输入 NAND 上。只有地址完全匹配时输出才会变 LOW——一种紧凑、快速、并且在 CMOS 中扩展性良好的实现。
动手实践:用 NAND 门搭建半加器(HALF_ADDER)
由 5 个 NAND 门构成的 HALF_ADDER 是一个经典的设计练习,把通用性和实际门级经济性巧妙地结合在一起。
HALF_ADDER 需要两个输出:和 () 与进位 ()。XOR 函数本身需要 4 个 NAND 门,AND 函数需要 2 个。直观相加是 6 个门。但通过共享一个中间信号,你可以把它压缩到 5 个:
- 门 1: 输入 A 和 B,输出 。
- 门 2: 输入 A 和 ,输出 。
- 门 3: 输入 B 和 ,输出 。
- 门 4: 输入 和 ,输出和()。
- 门 5: 输入 和 (短接),输出进位()。
门 5 实际上就是对 的取反,而 ,取反后就是 ——也就是进位。门 1 的输出 在 XOR 构造和进位路径之间共享,从而省下了一个门。
请在 digisim.io 上搭出这个电路,并对照半加器真值表验证两个输出。再用示波器确认”和”输出的延迟比”进位”输出略长(三级门级 vs 两级门级)。
课程关联
本文与以下内容相关:
- 无名英雄:NOR 门如何造就阿波罗 —— 另一个通用门。
- 传输延迟 —— 延迟堆叠如何影响真实设计。
- SR 锁存器 —— 基于 NAND 的存储单元,以及触发器的基础。
你的挑战
仅用 NAND 门搭建一个 2 选 1 多路复用器。布尔表达式为 。借助 德摩根变换,你完全可以仅用 NAND 来实现它。数一数你用了多少个门,并用示波器测一测关键路径延迟。