NAND ゲート:すべてのデジタル論理を支える唯一の構成要素
NAND ゲートは機能完備です。AND、OR、NOT、XOR、メモリセルはすべて NAND だけで構築できます。CMOS の経済性が NAND を標準セルの主役にしました。

TL;DR: NAND ゲートはすべての入力が 1 でない限り 1 を出力します()。これは機能完備であり、他のすべてのブール関数を NAND ゲートだけで実装できます。CMOS シリコン上では NAND は NOR より少ないトランジスタ数で済み、スイッチング速度も速いため、現代の標準セルライブラリで主役を張り、「NAND フラッシュ」がその名を冠する所以ともなっています。
電子部品商から入手できる 74HC00 IC は、14 ピン DIP パッケージに 4 つの NAND ゲートを収めて数セントで売られています。しかしこの目立たないチップは ── そして現代のあらゆるプロセッサに刻み込まれた数十億の NAND ゲートは ── 工学史上もっとも大量に製造された論理構造を表しているのです。
本記事では NAND ゲートを実用的・物理的なコンポーネントとして取り上げます:CMOS シリコン上でどう構築されるか、どの実 IC がそれを実装しているか、そのデータシートが何を語っているか、そしてなぜ半導体経済学が NAND ゲートを商用デジタルシステムの主たる構成要素にしたのかを掘り下げます。
NAND ゲート:駆け足のおさらい
本質的に、NAND ゲートは AND ゲートに NOT ゲートを続けたものです。2 つ以上の入力を受け取り、すべての入力が同時に HIGH である場合を除いて HIGH 出力 (1) を生成し、その例外時には LOW 出力 (0) を生成します。
真理値表
| 入力 A | 入力 B | 出力 Y |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
ブール式
ド・モルガンの定理 により、これは と等価であり、NAND ゲートが「入力反転 OR ゲート」という双対的な性質を持つことを示しています。
CMOS による実装:なぜ NAND はシリコンの自然な選択肢なのか
NAND が商用 IC 設計を支配する理由を理解するには、トランジスタ・レベルまで降りて見る必要があります。CMOS テクノロジーでは、すべての論理ゲートは 2 つの相補的なネットワークで構成されています:
- プルダウンネットワーク (PDN):出力をグランド () に接続する NMOS トランジスタ群。
- プルアップネットワーク (PUN):出力を電源電圧 () に接続する PMOS トランジスタ群。
2 入力 NAND ゲートでは、PDN は 2 つの NMOS トランジスタを 直列 に、PUN は 2 つの PMOS トランジスタを 並列 に持ちます。この配置には決定的な利点があります:NMOS トランジスタ(電子をキャリアとして使用)は本質的に PMOS トランジスタ(正孔をキャリアとして使用)より高速です。高速な NMOS を直列に、低速な PMOS を並列に配置することで、NAND ゲートは最小限のトランジスタサイズで均衡のとれた立ち上がり/立ち下がり時間を実現します。
これを NOR ゲートと比較してみましょう。NOR では PMOS トランジスタが直列になります。直列の PMOS は抵抗が増し、プルアップ遷移が遅くなり、それを補うためにより幅広い(大きい)トランジスタが必要になります。これが、CMOS において 2 入力 NAND ゲートが わずか 4 トランジスタ で済み、等価な NOR ゲートより少ないシリコン面積で実装できる理由です。
対照的に、AND ゲートは NAND ゲートにインバータを続けた構造を必要とし ── 合計 6 トランジスタ ── となります。この 50% のトランジスタ・オーバーヘッドが、ASIC 設計フローの合成ツールが可能な限り NAND ベースの実装を選好する理由です。
実 IC:74HC00 と CD4011
NAND ゲートは TTL(トランジスタ・トランジスタ論理)ファミリ初期の頃から個別 IC として入手可能でした。広く使われている 2 つの NAND ゲート IC は、異なる技術世代を象徴しています:
74HC00:高速 CMOS
74HC00 は 14 ピン DIP(または SOIC)パッケージに収まったクアッド 2 入力 NAND ゲートです。74HC(高速 CMOS)ファミリに属し、おそらく教育用やプロトタイピングの場面で最も広く使われている論理 IC です。
主要なデータシート・パラメータ( = 5V、25°C での代表値):
| パラメータ | 記号 | 代表値 |
|---|---|---|
| 電源電圧 | 2V〜6V | |
| 伝搬遅延 (L→H) | 9 ns | |
| 伝搬遅延 (H→L) | 9 ns | |
| 出力電流(ソース) | -4 mA | |
| 出力電流(シンク) | 4 mA | |
| 待機電流 | 1 µA | |
| ファンアウト(74HC 入力対象) | — | 約 10 |
ピン配置(14 ピン DIP):
- ピン 1, 2 → ゲート 1 入力;ピン 3 → ゲート 1 出力
- ピン 4, 5 → ゲート 2 入力;ピン 6 → ゲート 2 出力
- ピン 9, 10 → ゲート 3 入力;ピン 8 → ゲート 3 出力
- ピン 12, 13 → ゲート 4 入力;ピン 11 → ゲート 4 出力
- ピン 7 → GND;ピン 14 →
CD4011:クラシック CMOS
CD4011 は 4000 シリーズ・ファミリの CMOS カウンターパートです。電源電圧範囲がより広い(3V〜18V)ものの、伝搬遅延は遅い(5V で代表的に 50〜125 ns)です。利点は超低消費電力と広い電源電圧許容範囲で、電池駆動や工業用アプリケーションで人気があります。
いつどちらを使うか:
- ブレッドボードのプロジェクトや 1 MHz を超えるクロックに同期する場合は 74HC00 を使います。
- 速度が重要でない、低電力・広電圧範囲のアプリケーションには CD4011 を使います。
タイミング仕様:データシートを読む
本格的な設計作業では、データシートの伝搬遅延の数値があなたの制約となります。これらの数値が実務で何を意味するか見ていきましょう。
74HC00 ゲートは代表的な が 9 ns です。3 つの NAND ゲートを連鎖させると(例えば NAND のみで OR ゲートを構築する場合)、クリティカル・パス全体の遅延はおおよそ ns になります(信号は入力インバータと最終 NAND を通過するのであり、すべての入力で 3 つのゲートを直列に通るわけではありません)。
50 MHz(20 ns のクロック周期)では、タイミング・マージンはわずか 2 ns しか残りません。100 MHz では、遅延がクロック周期そのものを超えてしまいます。これが、高速設計が個別の NAND ゲートから OR を構築するのではなく、標準セルライブラリの専用 OR セルを使う理由です。
よくある落とし穴:伝搬遅延の積み重ね
すべてを NAND ゲートで構築すると、各段で遅延が累積します。NAND ベースの OR ゲートはクリティカル・パス遅延が 、NAND ベースの XOR は (3 ゲート段)になります。複雑な回路では、これら積み重なった遅延が最大クロック周波数を制限し、タイミング・ハザード ── 異なる経路の信号が異なる時刻に到達することで一時的に誤った出力が現れる グリッチ を引き起こします。
OSCILLOSCOPE による検証
digisim.io で伝搬遅延の積み重ねを観察するには、NAND ベースの OR ゲート(NAND 3 つ)とネイティブの OR ゲートを並べて構築します。両回路に同じ CLOCK 信号を供給します。OSCILLOSCOPE の 3 チャンネルを接続します:1 つを CLOCK 入力に、もう 1 つをネイティブ OR の出力に、もう 1 つを NAND ベース OR の出力に。
両方の出力がクロックを追従しているのが見えますが、NAND ベース版は右にさらにシフトしているはずです。その追加の水平方向のオフセットは、NAND のみの構成を使うことで支払う「遅延税」です。
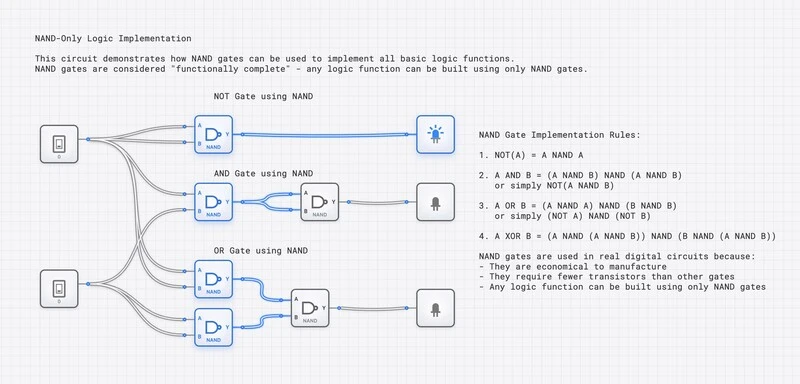
製造上の優位性:なぜ NAND がシリコン戦争に勝ったのか
IC 製造における NAND ゲートの支配は偶然ではありません。それは相互に関連する 3 つの優位性に由来します:
1. トランジスタ数
2 入力 NAND ゲートは 4 トランジスタを使います。AND ゲートには 6 つ(NAND + インバータ)が必要です。OR ゲートにも 6 つ(2 つのインバータ + NAND)が必要です。1 つのダイに 100 億トランジスタを詰め込むとき、ゲート単位のトランジスタ数を 33% 削減することは、より小さなダイ面積、より高い歩留まり、そしてより低いチップ単価へと直結します。
2. 速度
NMOS プルダウンネットワーク(NAND の速度上クリティカルな経路)が中程度の抵抗の直列トランジスタしか持たず、PMOS プルアップネットワークが並列の(低抵抗の)トランジスタを持つため、NAND ゲートは等価な NOR ゲートよりも高速なスイッチングを実現します。先進プロセスノード(7 nm、5 nm、3 nm)では、この速度優位性が数十億のゲートにわたって複利的に作用します。
3. 標準セルライブラリ
現代のチップ設計はファウンドリが提供する事前特性化されたゲート・レイアウトの集合体である標準セルライブラリに依存しています。これらのライブラリは大きく NAND 寄りに偏っています。代表的なライブラリは NAND2、NAND3、NAND4、さらには NAND2X2(駆動能力 2 倍の NAND)セルを提供し、それぞれ面積、速度、電力に最適化されています。EDA 合成ツールはあなたの RTL(レジスタ転送レベル)設計をこれらのセルにマッピングし、最適化器は最良の面積・遅延・電力の積を提供することから自然に NAND ベースの実装を選びます。
実世界の応用
NAND フラッシュメモリ
最も有名な応用がその名を冠しています:NAND フラッシュ。NAND フラッシュメモリでは浮遊ゲートトランジスタが直列に接続されています ── これは NAND ゲートの NMOS プルダウンネットワークと同じトポロジーです。この直列接続により NAND フラッシュは NOR フラッシュ(トランジスタが並列)より高密度になり、現代の SSD、USB ドライブ、スマートフォンの巨大なストレージ容量を可能にしています。
ASIC アドレスデコーダ
プロセッサ内部では、アドレスデコーダがどのメモリ位置や周辺機器がアクセスされているかを判断します。多入力 NAND ゲートは「この厳密なビットパターンに一致するか」という関数を自然に実装します。4 ビットアドレス 1101 であれば、デコーダは 3 番目のビット(0)を反転して 4 つすべてのラインを 4 入力 NAND に供給します。出力はアドレスが完全に一致したときのみ LOW になります ── CMOS でうまくスケールするコンパクトかつ高速な実装です。
ハンズオン:NAND ゲートで HALF_ADDER を構築する
5 つの NAND ゲートを使った HALF_ADDER は、万能性とゲート経済性を結びつける古典的な設計演習です。
HALF_ADDER は 2 つの出力を必要とします:Sum () と Carry ()。XOR 関数は単独で 4 つの NAND ゲートを必要とし、AND 関数は 2 つを必要とします。素朴に考えれば 6 ゲートです。しかし中間信号を共有することで、5 ゲートで実現できます:
- ゲート 1:入力 A と B。出力は 。
- ゲート 2:入力 A と 。出力は 。
- ゲート 3:入力 B と 。出力は 。
- ゲート 4:入力 と 。出力は Sum ()。
- ゲート 5:入力 と (同じ信号を両入力に接続)。出力は Carry ()。
ゲート 5 は単に にインバータを適用したもので、これは を反転すると ── キャリーになります。ゲート 1 の出力 () は XOR 構成とキャリー経路で共有され、これにより 1 ゲート節約されます。
これを digisim.io で組み立て、両方の出力を半加算器の真理値表と照合してください。OSCILLOSCOPE を使って Sum 出力が Carry 出力よりわずかに長い遅延を持つこと(3 ゲート段対 2 ゲート段)を確認しましょう。
カリキュラムでのつながり
本記事は以下と関連しています:
- 縁の下の力持ち:NOR ゲートはいかにアポロを構築したか ── もう一つの万能ゲート。
- 伝搬遅延 ── 遅延の積み重ねが実設計にどう影響するか。
- SR ラッチ ── NAND ベースのメモリセルとフリップフロップの基礎。
チャレンジ
2 対 1 マルチプレクサ を NAND ゲートだけで構築してみましょう。ブール式は です。ド・モルガン変換 を使えば、これを完全に NAND で実装できます。ゲート数を数え、OSCILLOSCOPE でクリティカル・パスの遅延を計測してください。