8対1マルチプレクサ
概要
- 目的: 8対1マルチプレクサは、8つの入力信号から1つを選択して単一の出力ラインに転送するデジタル回路で、複数のソースから共通の宛先へデータをルーティングするデジタル制御スイッチとして機能します。
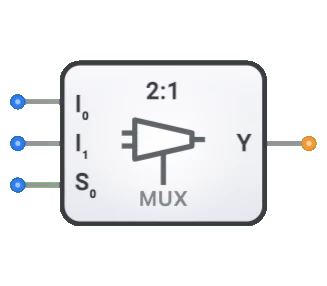
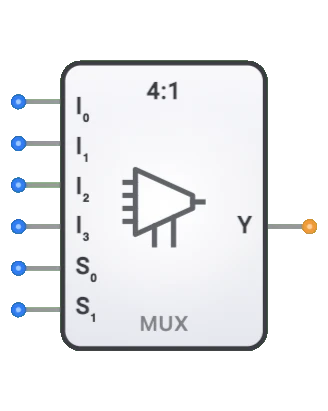
- 記号: 通常、8つのデータ入力(D0-D7)、3つのセレクト入力(S0-S2)、および1つの出力(Y)を持つ長方形のブロックとして表されます。
- DigiSim.ioでの役割: デジタルシステムにおけるデータ選択、パスルーティング、および複数のデータソースが共通の経路を共有できるようにすることでハードウェアの複雑さを低減する基本コンポーネントとして機能します。

機能説明
論理動作
8対1マルチプレクサは、3本のセレクトラインのバイナリ値に基づいて、8つの入力信号のうち1つを出力にルーティングします。セレクトラインは、どの入力チャネルが出力に接続されるかを決定する3ビットアドレスとして機能します。
真理値表:
| S2 | S1 | S0 | Output Y |
|---|---|---|---|
| 0 | 0 | 0 | D0 |
| 0 | 0 | 1 | D1 |
| 0 | 1 | 0 | D2 |
| 0 | 1 | 1 | D3 |
| 1 | 0 | 0 | D4 |
| 1 | 0 | 1 | D5 |
| 1 | 1 | 0 | D6 |
| 1 | 1 | 1 | D7 |
入力と出力
入力:
- D0-D7: 8つの1ビットデータ入力。そのうちの1つが出力にルーティングされます。
- S0: 3ビットセレクト入力の最下位ビット(LSB)。
- S1: 3ビットセレクト入力の中間ビット。
- S2: 3ビットセレクト入力の最上位ビット(MSB)。
出力:
- Y: 選択された入力の値を反映する単一の1ビット出力。
設定可能なパラメータ
- イネーブル制御: 一部の実装では、出力を無効化できる追加のイネーブル入力が含まれます。
- 出力タイプ: スタンダード、スリーステート、またはオープンコレクタ出力構成。
- アクティブレベル: セレクト入力とイネーブル信号がアクティブハイかアクティブローか。
- 伝搬遅延: 出力が選択された入力の変化を反映するまでの時間。
DigiSim.ioでの視覚的表現
8対1マルチプレクサは、左側に8つのデータ入力ピン(D0-D7)と3つのセレクト入力ピン(S0-S2)、右側に単一の出力ピン(Y)を持つ長方形のブロックとして表示されます。回路に接続すると、接続ワイヤの色の変化によってアクティブなデータパスを視覚的に示します。
教育的価値
主要概念
- データ選択: デジタルシステムが複数のデータソースからどのように選択するかを実演します。
- バイナリアドレッシング: バイナリコードが特定の入力チャネルをどのように選択できるかを示します。
- 信号ルーティング: データ経路とスイッチングの基本概念を説明します。
- リソース共有: 複数のソースが共通の宛先を共有できる方法を強調します。
- デジタル制御: デジタル信号を使用して信号フローを制御する概念を提示します。
学習目標
- マルチプレクサがセレクトラインの値に基づいて複数の入力信号からどのように選択するかを理解する。
- バイナリセレクトコードと入力選択の関係を学ぶ。
- マルチプレクサがデジタルシステムで効率的なリソース共有をどのように可能にするかを認識する。
- データルーティングと選択回路の設計にマルチプレクサの概念を適用する。
- データ変換、通信、制御システムにおけるマルチプレクサの役割を理解する。
- デジタルシステムにおける信号ルーティングの分析と設計のスキルを身につける。
使用例/シナリオ
- データバス選択: 8つのデータソースの1つを共通のデータバスに接続する。
- ALU演算選択: 異なる算術演算や論理演算の結果から1つを選択する。
- メモリアドレスマルチプレクシング: メモリアドレスの異なる部分から選択する。
- パラレル-シリアル変換: パラレルワードからビットを順次選択してシリアルストリームを作成する。
- テスト機器: 複数のテストポイントの1つを測定機器にルーティングする。
- 関数生成: 異なる関数ジェネレータまたは波形から選択する。
- 入力デバイス選択: コンピュータシステムで複数の入力周辺機器から選択する。
- 信号ソース選択: 複数の信号ソースの1つを処理ユニットにルーティングする。
技術ノート
- 8対1マルチプレクサは、3対8デコーダと追加の論理ゲートを使用して実装できます。
- 選択式: Y = D(S2×4 + S1×2 + S0)、本質的にバイナリセレクト値を対応する入力に変換します。
- 伝搬遅延は技術に応じて通常5-20nsで、セレクトから出力への変化はデータから出力への変化よりも通常遅くなります。
- セレクトラインの遷移中に複数のビットが同時に変化すると、瞬間的なグリッチが発生する場合があります。
- カスケード接続された2対1マルチプレクサ(7つの2対1MUXが必要)を使用したツリー実装は、より均一なタイミングを提供します。
- 一般的なIC実装には、74151(単一8対1マルチプレクサ)および74251(スリーステート出力付き)があります。
- DigiSim.ioでは、マルチプレクサはセレクト入力に基づく適切な信号ルーティングを示し、実際のマルチプレクサ回路の選択動作を正確にモデル化します。
特性
入力構成:
- 8つのデータ入力(D0-D7)
- 3つのセレクト入力(S0-S2)
- セレクトラインがどのデータ入力を出力にルーティングするかを決定
- 標準的なデジタルロジックレベルと互換
- 入力インピーダンスは通常高い
出力構成:
- 単一出力(Y)
- 出力は選択された入力信号を反映
- ファンアウト能力は技術的実装に依存
- 一部の実装では追加の出力機能(イネーブル/ディセーブルなど)を含む場合がある
機能:
- セレクト入力のバイナリ値に基づいて8つの入力データラインの1つを選択
- 選択式: Y = D(S2×4 + S1×2 + S0)
- 制御されたデータスイッチとして機能
- ノンブロッキング(一度にアクティブなパスは1つのみ)
- データ変換なし(入力がそのまま出力に渡される)
伝搬遅延:
- データ入力から出力: 通常5-15ns
- セレクト入力から出力: 通常7-20ns
- 技術依存(TTL、CMOS、BiCMOSなど)
- 入力チャネルによって異なる遅延が生じる場合がある
- セレクトラインの遷移で出力グリッチが発生する可能性がある
ファンアウト:
- 通常10-20の標準負荷を駆動
- 出力負荷が伝搬遅延に影響
- 高ファンアウトアプリケーションではバッファが必要な場合がある
消費電力:
- 静的電力は技術に依存(CMOSでは最小)
- 動的電力はスイッチング周波数とともに増加
- 消費電力は電圧の二乗に比例
- セレクトラインの遷移で追加電力を消費
- 最新の実装は非常に電力効率が高い
回路の複雑さ:
- 中程度の複雑さ
- 通常、デコーダとゲートで実装
- 3対8デコーダと8つのトランスミッションゲートまたはAND/ORロジックが必要
- セレクトラインの数に応じて指数関数的にスケール
- より広い選択機能のためにカスケード接続可能
実装方法
ディスクリートロジック実装
- 基本ゲート(AND、OR、NOT)から構築
- 3対8デコーダに続くANDゲートとORゲートを使用
- コンポーネント数は多いが柔軟な設計
- 特殊な要件に適応可能
- 教育目的や特殊なアプリケーションに適している
トランスミッションゲートアプローチ
- CMOSトランスミッションゲートをスイッチとして使用
- 低消費電力
- アナログ信号に対する優れた信号完全性
- 信号劣化が最小
- 一部の構成で双方向機能
集積回路実装
- 専用マルチプレクサICとして利用可能
- 74xxシリーズロジックファミリで一般的
- 例: 74151(単一8対1MUX)、74251(スリーステート出力付き)
- 各種技術オプション(TTL、CMOS、BiCMOS)
- イネーブル/ストローブ入力などの追加機能を含む場合がある
デコーダベースアプローチ
- 3対8デコーダを使用して選択信号を生成
- 各デコーダ出力が1つのデータパスを有効化
- 教育的文脈で一般的
- モジュラー設計アプローチ
- 動作の理解が容易
ツリーベース実装
- ツリー構造でカスケード接続された2対1マルチプレクサ
- 3レベルの2対1MUX(合計7つ)
- 一部のパスで伝搬遅延が削減
- より均一なタイミング特性
- より単純な構成要素
FPGA/ASIC実装
- ルックアップテーブル(LUT)または専用マルチプレクサセルを使用して実装
- 特定のパフォーマンス要件に合わせて構成可能
- 速度、面積、または電力に最適化
- 特殊なルーティングリソースを活用可能
- 効率のために他の機能と組み合わせ可能
アプリケーション
データ選択とルーティング
- 複数のデータソースからの選択
- コンピュータシステムでのバスマルチプレクシング
- メモリインターフェースでのアドレス/データマルチプレクシング
- 通信システムでのチャネル選択
- マイクロコントローラシステムでの周辺機器選択
パラレル-シリアル変換
- パラレルデータをシフトレジスタにロード
- 時分割マルチプレクシング
- パラレルデータストリームのシリアル化
- データフォーマッティングとパケット化
- スキャンパステスト実装
算術演算と論理演算
- ALUでの関数選択
- 複雑な組み合わせ論理の実装
- 関数のルックアップテーブル実装
- プログラマブルロジックアレイ
- 真理値表の実装
信号処理
- オーディオ/ビデオ機器での信号パス選択
- データ収集システムでのチャネル選択
- サンプルアンドホールドマルチプレクシング
- センサ入力選択
- DSPアプリケーションでの信号ルーティング
メモリシステム
- DRAMインターフェースでのアドレスマルチプレクシング
- メモリシステムでのバンク選択
- メモリチップ選択
- キャッシュアクセス制御
- メモリインターリービング
制御システム
- ステートマシンでのモード選択
- 制御パスの切り替え
- 冗長システムの切り替え
- テストとデバッグパスの選択
- 構成の選択
波形生成
- 異なる波形ソースの選択
- プログラマブル関数ジェネレータ
- シーケンス生成
- テスト用パターン生成
- オーディオシンセシスアプリケーション
制限事項
伝搬遅延
- セレクトから出力までの大きな遅延
- 入力によって異なる遅延パス
- 負荷とともに遅延が増加
- 高速アプリケーションでは重要
- 同期システムでタイミング違反を引き起こす可能性
選択変更時のグリッチ
- セレクト遷移中の一時的な無効出力
- シーケンシャルシステムでエラーが伝搬する可能性
- システムクロックとの同期が必要な場合がある
- セレクトラインデコーディングロジックのハザード
- 特定の実装方法でより顕著
ファンアウトの制限
- 出力駆動能力の制約
- 複数の負荷に対してバッファリングが必要な場合がある
- 高容量性負荷での信号劣化
- ファンアウトが高いほど遅延が増加
- セレクトラインの負荷がパフォーマンスに影響する可能性
スケーラビリティの課題
- 入力数とともに複雑さが指数関数的に増加
- より大きなマルチプレクサにはより多くのセレクトラインが必要
- サイズとともに消費電力が増加
- 物理的レイアウトが困難になる
- サイズとともに伝搬遅延が増加
信号完全性の問題
- 近接してルーティングされたチャネル間のクロストーク
- 一部の実装での信号減衰
- 実装によってノイズ感度が異なる
- CMOSトランスミッションゲートでの電荷注入
- 電源電圧感度
回路実装の詳細
AND-ORロジックを使用した基本8対1MUX
graph TD
D0[D0] --> AND0[AND Gate 0]
S0N[S0'] --> AND0
S1N[S1'] --> AND0
S2N[S2'] --> AND0
D1[D1] --> AND1[AND Gate 1]
S0[S0] --> AND1
S1N --> AND1
S2N --> AND1
D2[D2] --> AND2[AND Gate 2]
S0N --> AND2
S1[S1] --> AND2
S2N --> AND2
D3[D3] --> AND3[AND Gate 3]
S0 --> AND3
S1 --> AND3
S2N --> AND3
D4[D4] --> AND4[AND Gate 4]
S0N --> AND4
S1N --> AND4
S2[S2] --> AND4
D5[D5] --> AND5[AND Gate 5]
S0 --> AND5
S1N --> AND5
S2 --> AND5
D6[D6] --> AND6[AND Gate 6]
S0N --> AND6
S1 --> AND6
S2 --> AND6
D7[D7] --> AND7[AND Gate 7]
S0 --> AND7
S1 --> AND7
S2 --> AND7
AND0 --> OR[OR Gate]
AND1 --> OR
AND2 --> OR
AND3 --> OR
AND4 --> OR
AND5 --> OR
AND6 --> OR
AND7 --> OR
OR --> Y[Output Y]
注: S0'、S1'、S2'は反転(NOT)されたセレクト信号を表します
│ │
AND │
D4 ──►│ │
│ │
S0' ──►│ │
S1' ──►│ │
S2 ──►│ │
│ │
AND │
D5 ──►│ │
│ │
S0 ──►│ │
S1' ──►│ │
S2 ──►│ │
│ │
AND │
D6 ──►│ │
│ │
S0' ──►│ │
S1 ──►│ │
S2 ──►│ │
```